I've changed my CFLAGS, CXXFLAGS, LDFLAGS and USE varaiables and want to recompile. Is this http://gentoo-wiki.com/HOWTO_Doing_a_hu ... erge_world or this http://gentoo-wiki.com/HOWTO_Doing_a_hu ... scripts.sh the best way to do it or an I better to just do;
emerge --sync && layman -S && emerge -ueND system && emerge -ueND world && glsa-check -f all ?
I have only added USE variables. I take it I only have to do a revdep --rebuild if I remove USE variables right?
Thanks in advance.
CFLAGS Central (Part 2)
Message

Cflags :)
Hi,
I have Athlon64 3000+ Venice (SSE SSE2 SSE3 MMX 3DNOW) and actually i have set -march to athlon64.
I wonder if i can change it to -march=opteron since tests compiled with this flags are much faster?
I wonder if optimalizing software for opteron instead of athlon64 may cause any troubles?
THANKS!
mod edit: Merged here from Unsupported Software --Earthwings
I have Athlon64 3000+ Venice (SSE SSE2 SSE3 MMX 3DNOW) and actually i have set -march to athlon64.
I wonder if i can change it to -march=opteron since tests compiled with this flags are much faster?
I wonder if optimalizing software for opteron instead of athlon64 may cause any troubles?
THANKS!
mod edit: Merged here from Unsupported Software --Earthwings
- baigsabeeh
- Guru

- Posts: 520
- Joined: Wed Sep 28, 2005 7:51 pm
- Location: North Brunswick, NJ

Re: Cflags :)
They shouldn't because it's the same architecture. AMD released Socket 939 Opterons last year, so no shouldn't be any problems.Morpheouss wrote:Hi,
I have Athlon64 3000+ Venice (SSE SSE2 SSE3 MMX 3DNOW) and actually i have set -march to athlon64.
I wonder if i can change it to -march=opteron since tests compiled with this flags are much faster?
I wonder if optimalizing software for opteron instead of athlon64 may cause any troubles?
THANKS!
mod edit: Merged here from Unsupported Software --Earthwings
BSD > SysV > Linux
BSD FTW!
BSD FTW!

first of all,i read all the posts starting from page 1 from part1 and all of this (part2) thread..
the thing is that we didnt see any FINAL gcc optimization line..
whatever somebody show as his two cents somebody else deny it and drop it down and so on ..
does exist any final CFLAG line which gives you the best possible performance and safest possible system which i think can't go together you'll agree..
so.i own athlon xp 2500+(barton) and 1.5gigs of ram..
what would be the highest performing but still "safe" gcc optimization and what would be the most stable but no "snail" alike system optimizations?
same goes for intel cpu's..
thnxx
the thing is that we didnt see any FINAL gcc optimization line..
whatever somebody show as his two cents somebody else deny it and drop it down and so on ..
does exist any final CFLAG line which gives you the best possible performance and safest possible system which i think can't go together you'll agree..
so.i own athlon xp 2500+(barton) and 1.5gigs of ram..
what would be the highest performing but still "safe" gcc optimization and what would be the most stable but no "snail" alike system optimizations?
same goes for intel cpu's..
thnxx
Here goes with what makes KDE run so sweet for me (no flames please, disagreement with reasoning fine, but no flames):
CFLAGS="-O2 -march=<CPU> -pipe -fomit-frame-pointer -falign-jumps=4 -falign-labels=4 -falign-loops=4"
The align ones are the ones I really like as they give me smaller code (align stuff to word boundary, except for functions) while I still get the best optimisation gcc authors recommend for production (-O2 ofc.) If any of those aligns is not at a word boundary the compiler will be inserting NOPs, ie idle instructions that do nothing but waste a cycle as well as increase code size. The ``natural'' size iirc for an Athlon XP (which I have) is 16 or 32. (It's been a while since I settled on this.) Yeuch.
Technically, on a CISC machine, like Intel, the compiler will insert nops if the code happens to use say a 2 byte insn, but I don't want my branches or loops going back to a non-word boundary. If I were on a 64bit arch, i'd use 8 (ie the register word size, which is what I call natural for alignment of such things.) Functions, it makes sense to allow the compiler to align, since the program will never execute the NOPs before the function definition.
I'd love to hear what people think (including why this is stupid ofc ;)
CFLAGS="-O2 -march=<CPU> -pipe -fomit-frame-pointer -falign-jumps=4 -falign-labels=4 -falign-loops=4"
The align ones are the ones I really like as they give me smaller code (align stuff to word boundary, except for functions) while I still get the best optimisation gcc authors recommend for production (-O2 ofc.) If any of those aligns is not at a word boundary the compiler will be inserting NOPs, ie idle instructions that do nothing but waste a cycle as well as increase code size. The ``natural'' size iirc for an Athlon XP (which I have) is 16 or 32. (It's been a while since I settled on this.) Yeuch.
Technically, on a CISC machine, like Intel, the compiler will insert nops if the code happens to use say a 2 byte insn, but I don't want my branches or loops going back to a non-word boundary. If I were on a 64bit arch, i'd use 8 (ie the register word size, which is what I call natural for alignment of such things.) Functions, it makes sense to allow the compiler to align, since the program will never execute the NOPs before the function definition.
I'd love to hear what people think (including why this is stupid ofc ;)
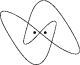
Shouldn't these numbers be 3 so that either 0,1,2,3 nops can be inserted so that you reach an address divisible by 4?steveL wrote:-falign-jumps=4 -falign-labels=4 -falign-loops=4
(For amd64, it appears to me that, similarly, these numbers should be 7 and not 8 as you suggested?)
However, I was unable to find out from the manpage what is the default for these number when you just use -O2 (or -O3):
To which power of two is then aligned in case of x86 or amd64?
And, moreover, if this number is not 4 or 8 respectively, why did the gcc-authors not choose the "processor-optimal" number?
Edit: Inserted forgotten not
Last edited by mv on Mon Aug 20, 2007 1:44 pm, edited 1 time in total.

This is is a good reference on optimization flags: http://gcc.gnu.org/onlinedocs/gcc-4.1.2 ... tions.htmlShouldn't these numbers be 3 [...]
To summarize, -falign-thing=N will align to the next power of 2 greater than N but only if no more than N bytes must be skipped to do so. So N=4 aligns to multiples of 8 only if that multiple is 4 or fewer bytes away. N=3 aligns to multiples of 4, always (since any multiple of 4 is always 3 or fewer bytes away).
I *think* the gcc defaults are something like N=8 for these, and 16 or even 32 for functions. But it has been a while since I looked (at the source
Edit/clarification: The defaults are processor-dependent. I recall seeing numbers like N=8 for common processors last time I had looked (several years ago, for athlon).
Last edited by Akkara on Tue Aug 21, 2007 12:14 pm, edited 1 time in total.
Thanks for the information. So the defaults are not processor-dependent and thus certainly not processor-optimized (as I would have expected). So it seems that SteveL's suggestion (if you choose 3 or 7, respectively) has only advantages and no disadvantages.Akkara wrote:I *think* the gcc defaults are something like N=8 for these, and 16 or even 32 for functions. But it has been a while since I looked (at the source)
Edit: ...but on the above page, I read "if N is unspecified or 0 use a machine-dependent default". I think I also have to dive into the sources once I have time to find out which information is correct. However, I don't know how to find out for x86/amd64 which value is better... If the default is really processor dependent and >3 and SteveL is right that x86 cannot gain from an 8-byte alignment over an 4-byte alignment, this sounds to me like a bug of gcc.
Can anyone tell me whic CFLAGH I have to use for this cpu:
thx[/code]processor : 0
vendor_id : CyrixInstead
cpu family : 6
model : 1
model name : 6x86MX 2.5x Core/Bus Clock
stepping : 4
cpu MHz : 167.054
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : yes
fpu : yes
fpu_exception : yes
cpuid level : 1
wp : yes
flags : fpu de tsc msr cx8 pge cmov mmx cyrix_arr
bogomips : 335.01
This information was correct, at least for gcc-4.1.2. If you are interested in the defaults, they can be found in gcc/config/i386/i386.c in the procesor_target_table. Roughly speaking, on athlon chips a "bad" alignment apparently is less expensive than on intel chips (usually no more than align_*=7 is used by default for athlon; i486 and pentiumpro use the highest numbers 15 for align_loop)mv wrote:"if N is unspecified or 0 use a machine-dependent default".
Since I suppose that the gcc developers had considered the processor specifications when they wrote this table, I see no reason why we shouldn't trust in their informations. SteveL, do you have more information than just your intuition why a smaller choice should be preferable?
The defaults are processor-dependent. Sorry I wasn't clear about that in the previous reply.So the defaults are not processor-dependent
Regarding what the best numbers are:
It is related to pipeline depth, decode depth, and L1 cache-miss latency versus time spent executing pipelined no-ops. A processor like the P4 has a very long pipeline (30+ cycles if I recall - but don't take that as fact it has been a while), so it sees more detriment on a taken brance that hits near the end of a cache line, than an athlon with a shorter pipeline.
But there's secondary effects which can end up being significant: if using a smaller padding lets more useful code live in the L2 cache, the processor will not need to wait for the much slower main memory as much, giving faster overall execution even though the individual loops might be somewhat slower.
Nah it's just experience of assembler. A NOP is a NOP is a total waste of time and space, unless you happen to be timing something (aka busy-waiting.) (Or you're aligning.) Loop-unrolling, for instance, is from the days when CPUs didn't have caches at all (I'm reliably informed.) So yeah what Akkara said, about keeping small code in the caches when you can, but no hard evidence. Anecdotal yeah in that KDE runs much faster on Gentoo than anything else (ofc) and everyone else in gentoo-land complains about it, but it's easily fast enough for us to code on older machines, while still having full desktop installs with apache php and mysql on board.mv wrote:SteveL, do you have more information than just your intuition why a smaller choice should be preferable?
OFC nowadays, our 512MB is `lame'. One colleague started coding with less than 32KB for everything, and no disk, so it's all relative.
I experienced an enormous speed increase with loop unrolling on amd64. But perhaps it is really true that amd chips have usually less cache and smaller pipelines so that only on these chips this has a positive effect.steveL wrote:Loop-unrolling, for instance, is from the days when CPUs didn't have caches at all (I'm reliably informed.)
Hmm, it'll always be faster, if you ignore caching issues, since there is no dec and conditional branch. Since we're effectively going for -Os type smaller code, however, it's not something we do (since it always leads to larger code.) I can't see the NOPs being much use, even if the chip is supposed to pipeline better etc, since those NOPs will always be executed. But again I have no hard figures. I'd imagine alignment of loops is where it'd be the most use, since loops are usually executed several times, followed by functions (which we allow since the alignment won't put NOPs in the execution path.) The most common branch (jump to label) is on an IF (eg to avoid the else part) and is usually executed only once in that block. It may well be in a loop but in the absence of profiling or the coder telling the compiler which branch is likely, there's no way to know which branch will be run more often. If it is aligned, the label to which we branch will have NOPs before it, and whenever the CPU goes down the other path it will waste a few cycles (as well as the code being larger.)mv wrote:I experienced an enormous speed increase with loop unrolling on amd64. But perhaps it is really true that amd chips have usually less cache and smaller pipelines so that only on these chips this has a positive effect.steveL wrote:Loop-unrolling, for instance, is from the days when CPUs didn't have caches at all (I'm reliably informed.)
Interesting discussion though, I'm glad I posted (thought I'd get shot down.. ;) It'd be interesting to try some profiling of the standard options versus a set with the three align settings (and with and without unroll-loops.) Tricky bit is deciding on a set of benchmarks.
Meantime, we're setting ours to 3 (thanks Akkara) to get the smallest code we can while still using -O2 optimisation; I still find it hard to believe that a processor trips up on word boundaries. I'll let you know if things suddenly slow down. :-)
What happens is something like this:I still find it hard to believe that a processor trips up on word boundaries
Code: Select all
0 1 2 3 4 5 6 7 8 9 A B C D E F
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
000x | | |add b,c| | | | | | | | |add a,b| dec c |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
001x |cmp c,0|bne $C | | | | | | | | | | | | |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
. . .Let's say a loop starts with the "add a,b" instruction at address 0x000C. When the processor first jumps here, if the line isn't in cache it'll have to issue memory reads to fill the cache line (here illustrated as 16 bytes long, but modern processors have it longer - 32 I think maybe even 64). So that's a delay. And barely two instructions get down the pipe that there's another delay fetching the next cache line.
Earlier processors don't have as much in terms of cache but there's often a one-line buffer of sorts ahead of the instruction-decode logic that can execute a loop when it is entirely contained, without having to out to memory at all.
That is why it can be advantageous to align things. Depends on the specifics of the micro-architecture tho. What's good for one can be bad for another.
There's a part I don't understand of the -falign options:
According to the picture above, let's say a loop starts at, for example, address 0x0002. That's not bad at all - there's 14 bytes of good opcodes till the end. But let's say align=7 is set. It'll try to align to 8-byte boundaries, or address 0x0008. But now there's only 8 bytes left to the end, which is worse off for this configuration.
What I'd like to be able to say, is "align to 16, but only if you can skip 4 or less". But there doesn't seem to be any way of saying it. By saying align=3, it'll align everything to 4, making an interior alignment somewhat worse off -- Or at least I think. There's a lot of this stuff I don't understand fully either.
hi all!
i recently upgraded my hardware form a gool old athlon xp 1100 to this:
i use cpudynd so the real mhz rate is higher 
these are my settings in /etc/make.conf with the system running stable:
i read a post (i think here in this forum) with these suggested settings for CFLAGS with the same cpu like mine:
thx & greets
snIP3r
i recently upgraded my hardware form a gool old athlon xp 1100 to this:
Code: Select all
area52 ~ # cat /proc/cpuinfo
processor : 0
vendor_id : AuthenticAMD
cpu family : 15
model : 75
model name : AMD Athlon(tm) 64 X2 Dual Core Processor 3800+
stepping : 2
cpu MHz : 1000.000
cache size : 512 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 2
fpu : yes
fpu_exception : yes
cpuid level : 1
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt rdtscp lm 3dnowext 3dnow pni cx16 lahf_lm cmp_legacy svm cr8_legacy
bogomips : 2011.43
TLB size : 1024 4K pages
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management: ts fid vid ttp tm stc
processor : 1
vendor_id : AuthenticAMD
cpu family : 15
model : 75
model name : AMD Athlon(tm) 64 X2 Dual Core Processor 3800+
stepping : 2
cpu MHz : 1000.000
cache size : 512 KB
physical id : 0
siblings : 2
core id : 1
cpu cores : 2
fpu : yes
fpu_exception : yes
cpuid level : 1
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt rdtscp lm 3dnowext 3dnow pni cx16 lahf_lm cmp_legacy svm cr8_legacy
bogomips : 2011.43
TLB size : 1024 4K pages
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management: ts fid vid ttp tm stc
these are my settings in /etc/make.conf with the system running stable:
Code: Select all
CFLAGS="-O2 -march=k8 -pipe"
CXXFLAGS="${CFLAGS}"
# This should not be changed unless you know exactly what you are doing. You
# should probably be using a different stage, instead.
CHOST="x86_64-pc-linux-gnu"
MAKEOPTS="-j3"
should i add some of these settings?CFLAGS="-march=athlon64 -O2 -msse3 -mfpmath=sse,387 -pipe -ffast-math -m64"
thx & greets
snIP3r
Intel i3-4130T on ASUS P9D-X
Kernel 6.6.52-gentoo SMP
-----------------------------------------------
if your problem is fixed please add something like [solved] to the topic!
Kernel 6.6.52-gentoo SMP
-----------------------------------------------
if your problem is fixed please add something like [solved] to the topic!
snIP3r wrote:these are my settings in /etc/make.conf with the system running stable:i read a post (i think here in this forum) with these suggested settings for CFLAGS with the same cpu like mine:Code: Select all
CFLAGS="-O2 -march=k8 -pipe" CXXFLAGS="${CFLAGS}" # This should not be changed unless you know exactly what you are doing. You # should probably be using a different stage, instead. CHOST="x86_64-pc-linux-gnu" MAKEOPTS="-j3"should i add some of these settings?CFLAGS="-march=athlon64 -O2 -msse3 -mfpmath=sse,387 -pipe -ffast-math -m64"
Code: Select all
CFLAGS="-O2 -march=athlon64 -pipe -fomit-frame-pointer"My guess is that - as it seems to happen rather often - the description on the gcc manpage is not correct:Akkara wrote:What I'd like to be able to say, is "align to 16, but only if you can skip 4 or less". But there doesn't seem to be any way of saying it.
The earlier mentioned processor_target_table actually contains both of these quantities for each type of align* and each type of processor.
However, by "manual" options you can tweak only the "skip" quantities (which somewhat makes sense, since the first one is processor-specific).
For example, for i386 the numbers are 4 and 3 (i.e. align to 4 bytes, skipping 3 or less) for all types (functions/loops/...), but for amd64 the numbers are 16 and 7.
I have not looked at the code generation, but my guess is that this means: Skip up to 7 bytes to align to 16; if this is not possible, do not skip anything.
So, summarizing, my guess is: Setting -falign*=3 on amd64 is almost equivalent to -nofalign* except in 1/4 th of all cases where really the next 16 bytes boundary is reached by using only 3 or less nops.
Thanks for a nice explanation. The thing that gets me is that you're only talking about a problem on cache misses; to my mind the cache line isn't so significant here as the locality of code. It might need 3 or 10 lines for the function, but it's more about whether the function as a whole is in cache as opposed to the lines. Smaller code leads to less cache usage in the first place, and additionally there are no NOPs slowing things down. I can see the case for loops within a cache line as you explain though.Akkara wrote:This is a hypothetical processor since I don't know the details of x86 nor x_64 at this level.Code: Select all
0 1 2 3 4 5 6 7 8 9 A B C D E F +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ 000x | | |add b,c| | | | | | | | |add a,b| dec c | +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ 001x |cmp c,0|bne $C | | | | | | | | | | | | | +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ . . .
Let's say a loop starts with the "add a,b" instruction at address 0x000C. When the processor first jumps here, if the line isn't in cache it'll have to issue memory reads to fill the cache line (here illustrated as 16 bytes long, but modern processors have it longer - 32 I think maybe even 64). So that's a delay. And barely two instructions get down the pipe that there's another delay fetching the next cache line.
Earlier processors don't have as much in terms of cache but there's often a one-line buffer of sorts ahead of the instruction-decode logic that can execute a loop when it is entirely contained, without having to out to memory at all.
That is why it can be advantageous to align things. Depends on the specifics of the micro-architecture tho. What's good for one can be bad for another.
The asm coder in me just shies away from NOPs. I certainly wouldn't want any nops at all for branches in the general case (the most common of which is skipping a branch of an if.) Eg a simple if (c) code; the compiler will implement that as if (!c) jp endif; code; endif:
Where endif has to be aligned, the code part will always run through nops. Yeuch! So maybe we should even be thinking about 0 for branches.
I could well be missing something about cache lines or the alignment of jumps ofc :-)
I guess that depends on how often condition c is true. Seems most of the time, forward branches like that one are almost always taken. For example, if((g = getchar()) == EOF). That if will be true at most once per file read. Or the very common if(do_something(...) == FAILED) { recovery(); } Almost all of those are forward branches around conditions that are rarely true.Eg a simple if (c) code; the compiler will implement that as if (!c) jp endif; code; endif:
It is more than just cache although I wasn't clear about it (in part because I'm not an expert in this level of detail).The thing that gets me is that you're only talking about a problem on cache misses; to my mind the cache line isn't so significant here as the locality of code.
Instruction fetches tend to happen in cache-line chunks. Instruction decode tries to run ahead of instruction execution, parsing those crazy x86 opcodes into the specific control signals and scheduling fetches of operands so everything's ready by time it hits the execution pipe. If it starts near the end of a cache line it might not be able to get ahead enough before it needs to fetch the next cache line, causing pipeline "bubbles" - which are just microcode-inserted no-ops because the front-end didn't have anything else ready for it in time. Additionally the fetch traffic can sometimes interfere with operand fetch. Separate I and D L1 caches help in this regard but sometimes an operand is a text-segment constant using so-called PC-relative addressing which -- I think -- would fetched through the I cache.
So in the case of pipeline bubbles, the main difference between explicit noops inserted by the compiler, and the implicit noops inserted by i-fetch, is that explicit ones takes up memory, which reduces the effectiveness of the L2 cache since there's more junk in it and increases the load time since more data needs to be read from disk.
- dpetka2001
- l33t

- Posts: 804
- Joined: Fri Mar 04, 2005 1:11 pm
- kernelOfTruth
- Watchman

- Posts: 6111
- Joined: Tue Dec 20, 2005 10:34 pm
- Location: Vienna, Austria; Germany; hello world :)
- Contact:

CFLAGS -O2 versus -Os
Hi,
I'm currently recompiling world with the following
CFLAGS="-O2 -march=pentium-m -pipe -mfpmath=sse -falign-functions=64 -fforce-addr -Wno-error -fivopts -fmodulo-sched -ftree-loop-im -ftree-loop-ivcanon -msse -msse2 -mmmx -D_FORTIFY_SOURCE=2"
and CXXFLAGS
before that it was:
CFLAGS="-Os -march=pentium-m -pipe -mfpmath=sse -falign-functions=64 -fforce-addr -Wno-error -D_FORTIFY_SOURCE=2"
and the same for CXXFLAGS
on hardened, since my good 'ol laptop got a newer and faster harddrive 25 MB/s -> 45 MB/s I think I can afford having bigger binaries
for comparison:
before: df -h == 7.1 G
now: df -h == 9.1 G
this with approx 1400 packages including xfce4, gnome, kde and several more
(~ 140 packages left won't change that much anymore I think)
I didn't know that Os had that much of an impact on size
just wanted to let you know if you're on the verge of switching from O2 to Os or the other way around
Cheers
I'm currently recompiling world with the following
CFLAGS="-O2 -march=pentium-m -pipe -mfpmath=sse -falign-functions=64 -fforce-addr -Wno-error -fivopts -fmodulo-sched -ftree-loop-im -ftree-loop-ivcanon -msse -msse2 -mmmx -D_FORTIFY_SOURCE=2"
and CXXFLAGS
before that it was:
CFLAGS="-Os -march=pentium-m -pipe -mfpmath=sse -falign-functions=64 -fforce-addr -Wno-error -D_FORTIFY_SOURCE=2"
and the same for CXXFLAGS
on hardened, since my good 'ol laptop got a newer and faster harddrive 25 MB/s -> 45 MB/s I think I can afford having bigger binaries
for comparison:
before: df -h == 7.1 G
now: df -h == 9.1 G
this with approx 1400 packages including xfce4, gnome, kde and several more
(~ 140 packages left won't change that much anymore I think)
I didn't know that Os had that much of an impact on size
just wanted to let you know if you're on the verge of switching from O2 to Os or the other way around
Cheers
https://github.com/kernelOfTruth/ZFS-fo ... scCD-4.9.0
https://github.com/kernelOfTruth/pulsea ... zer-ladspa
Hardcore Gentoo Linux user since 2004
https://github.com/kernelOfTruth/pulsea ... zer-ladspa
Hardcore Gentoo Linux user since 2004
- Earthwings
- Bodhisattva

- Posts: 7753
- Joined: Mon Apr 14, 2003 8:13 pm
- Location: Germany

Code: Select all
CFLAGS="-march=i686 -maccumulate-outgoing-args -pipe -O2 -frtl-abstract-sequences -funsafe-loop-optimizations -Wunsafe-loop-optimizations -fstrict-aliasing -fno-trapping-math -fno-ident"
CXXFLAGS = "-march=i686 -maccumulate-outgoing-args -pipe -O2 -frtl-abstract-sequences -funsafe-loop-optimizations -Wunsafe-loop-optimizations -fstrict-aliasing -fno-trapping-math fno-ident -fvisibility-inlines-hidden"
-maccumulate-outgoing-args = Use SUB/MOV instead of PUSH in assembly.
-frtl-abstract-sequences
-funsafe-loop-optimizations = Lets assume people wont write infinite loops.
-Wunsafe-loop-optimization = Lets warn if someone does.
-fstrict-aliasing = integers are not floats.
-fno-trapping-math = lets assume people don't divide by zero.
-fno-ident = GCC ident information. throws in gcc compiler used, etc into binary.
The one thing I don't know though is will gcc still honor function inlining with -frtl-abstract-sequences?